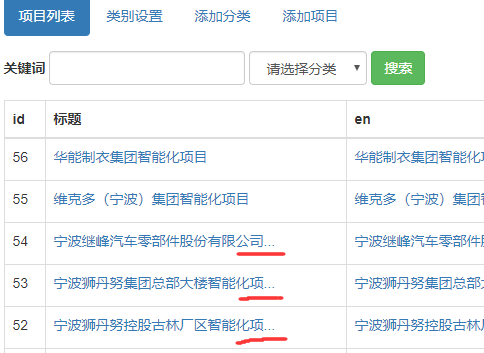
tp5.1和原生php一样,在截取新闻标题长度的时候都是一样的考虑.中文在字符串的处理中比英文要多考虑一些东西,因为英文占一个位,中文占二个位,在普通截取函数下有可能把中文一个字符截取成半个了(出现乱码)
# 函数解释:
msubstr($str, $start=0, $length, $charset=”utf-8″, $suffix=true)
/*
$str:要截取的字符串
$start=0:开始位置,默认从0开始
$length:截取长度
$charset=”utf-8″:字符编码,默认UTF-8
$suffix=true:是否在截取后的字符后面显示省略号,默认true显示,false为不显示
*/
function msubstr($str, $start=0, $length, $charset="utf-8", $suffix=true)
{
if(function_exists("mb_substr")){
if($suffix)
return mb_substr($str, $start, $length, $charset)."...";
else
return mb_substr($str, $start, $length, $charset);
}
elseif(function_exists('iconv_substr')) {
if($suffix)
return iconv_substr($str,$start,$length,$charset)."...";
else
return iconv_substr($str,$start,$length,$charset);
}
$re['utf-8'] = "/[x01-x7f]|[xc2-xdf][x80-xbf]|[xe0-xef][x80-xbf]{2}|[xf0-xff][x80-xbf]{3}/";
$re['gb2312'] = "/[x01-x7f]|[xb0-xf7][xa0-xfe]/";
$re['gbk'] = "/[x01-x7f]|[x81-xfe][x40-xfe]/";
$re['big5'] = "/[x01-x7f]|[x81-xfe]([x40-x7e]|xa1-xfe])/";
preg_match_all($re[$charset], $str, $match);
$slice = join("",array_slice($match[0], $start, $length));
if($suffix) return $slice."…";
return $slice;
}函数可以写在公共函数文件内 application/common.php中
在模版view视图中, 使用
{标题变量|msubstr=###,10}来调用